[논문리뷰] vAttention: PagedAttention 없이 LLM 서빙하기
클로드에게 최근 인프라 관련 논문 뭐 재밌는거 없냐고 물어보니까 vAttention 추천해줘서 읽어봤다.
논문 제목: vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
학회: ASPLOS ‘25
저자: Microsoft Research India 팀
0. 배경
KV Cache
LLM은 토큰을 한 번에 하나씩 순차적으로 생성한다.
[프롬프트: "오늘 날씨가"]
→ 모델 실행 → "좋다"
→ 모델 실행 → "고"
→ 모델 실행 → "합니다"
매번 새 토큰을 생성할 때마다 이전 토큰들의 Key(K), Value(V) 벡터가 필요한데, 이걸 매번 다시 계산하면 낭비다. 그래서 한번 계산한 K, V를 GPU 메모리에 저장해두고 재사용한다. 이게 KV Cache다.
특성:
- 토큰당 수십~수백 KB (모델마다 다름)
- iteration마다 정확히 1토큰씩 선형 증가 (예측 가능)
- 추론 시 GPU 메모리의 대부분을 차지
PagedAttention이 해결한 것
요청의 최종 길이는 모르기 때문에 메모리 관리가 어렵다.
Request A: 프롬프트 100 토큰 → 최종 500 토큰?
Request B: 프롬프트 50 토큰 → 최종 2000 토큰?
vLLM의 PagedAttention은 이를 블록 단위로 나누어 동적으로 할당하는 방식으로 해결했다.
자세한 내용은 이전 vLLM 논문 리뷰 참고
1. 문제
PagedAttention을 쓰면 성능이 최대 42% 저하된다.
메모리 효율은 좋아졌지만, 실제 inference 속도가 크게 느려진다는게 문제다.
2. 원인
PagedAttention이 user space에서 직접 블록 단위 메모리 관리를 하면서 소프트웨어 오버헤드가 발생한다.
GPU의 메모리 할당 방식
GPU는 CPU와 다르게 cudaMalloc이 즉시 물리 메모리를 할당한다.
# CPU: 실제 접근할 때 물리 메모리 할당 (lazy)
cpu_buffer = malloc(1GB)
# GPU: 즉시 1GB 전부 할당 (eager)
gpu_buffer = cudaMalloc(1GB)
PagedAttention의 구조
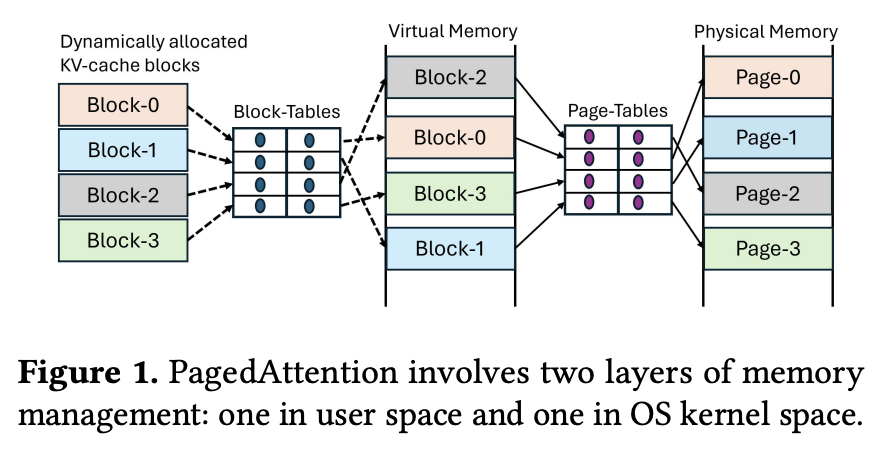

vLLM은 이 문제를 해결하기 위해 블록 단위로 메모리를 관리한다.
시점 1: 토큰 1~16개 → Block-0 할당
시점 2: 토큰 17~32개 → Block-1 할당
시점 3: 토큰 33~48개 → Block-2 할당
각 블록을 따로 cudaMalloc 했으니까 GPU 메모리에서 연속된 위치에 있지 않다.
GPU 메모리:
[...][Block-0][...빈 공간...][Block-2][Block-1][...]
0x1000 0x5000 0x3000
그래서 Attention 계산할 때 점프가 필요하다:
K[0~15]는 0x1000에서
K[16~31]는 0x3000에서 ← 점프!
K[32~47]는 0x5000에서 ← 또 점프!
때문에 Block-Table로 주소를 추적해야 한다:
// PagedAttention 커널
for (i = 0; i < seq_len; i++) {
block_idx = i / BLOCK_SIZE;
offset = i % BLOCK_SIZE;
addr = block_table[block_idx]; // 추가 lookup!
k = K[addr + offset];
}
매 토큰마다 소프트웨어가 주소를 계산하고, 이게 GPU 코어 사이클을 소모한다.
이게 최대 42% 성능 저하의 원인이다.
3. 솔루션
핵심 아이디어
가상 메모리는 연속으로 유지하고, 물리 메모리만 동적 할당
Virtual Memory (커널이 보는 것)
[────────── 연속된 큰 공간 ──────────]
↓ CUDA VMM API가 매핑
Physical Memory (실제 GPU 메모리)
[Page][Page][...흩어져 있어도 OK...][Page]
PagedAttention: 커널 코드가 직접 주소 계산
addr = block_table[block_idx];
k = K[addr + offset];
vAttention: 하드웨어가 알아서 변환
k = K[i]; // GPU MMU가 가상→물리 변환
소프트웨어 오버헤드를 하드웨어로 옮겨서 빠르다.
vLLM은 , CUDA VMM API가 2MB 페이지만 지원하기 때문에 위와 같이 유저 스페이스에서 구현
따라서, 토큰당 KV Cache: ~128KB (Llama-3-8B 기준). 2MB 페이지 쓰면: 토큰 1개만 써도 2MB 점유 → 낭비
구현
NVIDIA 오픈소스 드라이버 수정해서 64KB 페이지 지원 추가
| 기존 CUDA API | vAttention API |
|---|---|
cuMemMap (2MB) |
vMemMap (64KB) |
cuMemCreate (2MB) |
vMemCreate (64KB) |
또한, API 호출 latency가 높기 때문에, cuMemMap 한 번 호출: ~40μs → 매 iteration마다 호출하면 오버헤드. 백그라운드에서 미리 할당 (compute와 overlap)하여 해결. (Deferred reclamation: 요청 끝나도 바로 회수 안 하고, 다음 요청이 재사용)
4. 결과
| PagedAttention | vAttention | |
|---|---|---|
| 가상 메모리 | 비연속 | 연속 ✓ |
| 물리 메모리 | 비연속 | 비연속 (동일) |
| 점프 처리 | 소프트웨어 (느림) | 하드웨어/GPU MMU (빠름) |
| Block-Table | 필요 | 불필요 |
| 기존 커널 수정 | 필요 | 불필요 ✓ |
- Prefill throughput: PagedAttention 대비 최대 1.26× 향상
- End-to-end throughput: 최대 1.23× 향상 (long-context)
- Portability: FlashAttention-3 등 새 커널 수정 없이 바로 사용 가능
5. 마무리
PagedAttention의 아이디어(동적 메모리 할당)는 좋았지만, 구현 방식(user space 블록 관리)이 성능 저하를 일으켰다. vAttention은 같은 목표를 CUDA VMM으로 달성해서 성능 문제를 해결했다.
Static Allocation (기존)
→ 메모리 낭비 심함, 배치 크기 작음
PagedAttention (vLLM)
→ 동적 할당으로 메모리 효율 ↑
→ 단, user space에서 구현 → 가상 메모리까지 비연속
→ 소프트웨어 오버헤드 발생 (최대 42% 성능 저하)
vAttention
→ 동적 할당 (같은 목표)
→ CUDA VMM 활용 (더 나은 구현)
→ 가상 메모리 연속 유지 → 하드웨어가 점프 처리
→ 빠르고 (1.26×), 기존 커널 수정 불필요
개인적으로 인상 깊었던 부분은 “어느 레벨에서 추상화할 것인가”의 중요성이다. PagedAttention은 application level에서 메모리를 관리했고, vAttention은 system level(CUDA VMM)을 활용했다. 같은 문제를 푸는데도 어느 레벨에서 해결하느냐에 따라 성능이 크게 달라진다는 걸 보여준다.
또 하나는 오픈소스 드라이버를 수정해서 64KB 페이지를 지원했다는 점이다. 기존 API의 제약을 그대로 받아들이지 않고, 필요하면 직접 수정하는 것도 방법이라는 걸 보여준다. 하지만, 이게 가능한 사람이 얼마나 될까.. 생각했다.
참고
댓글남기기